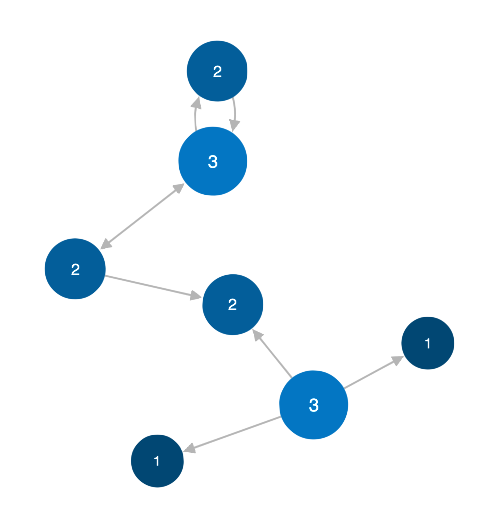
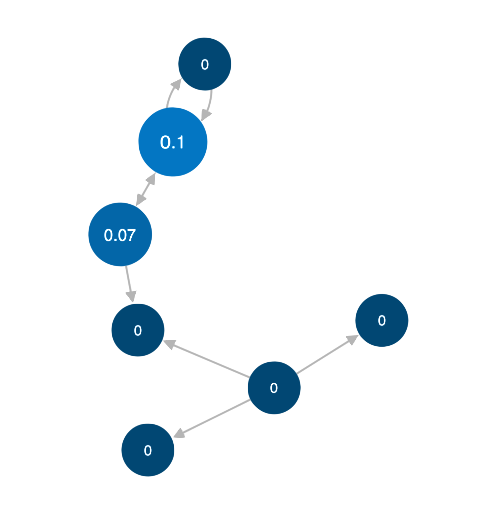
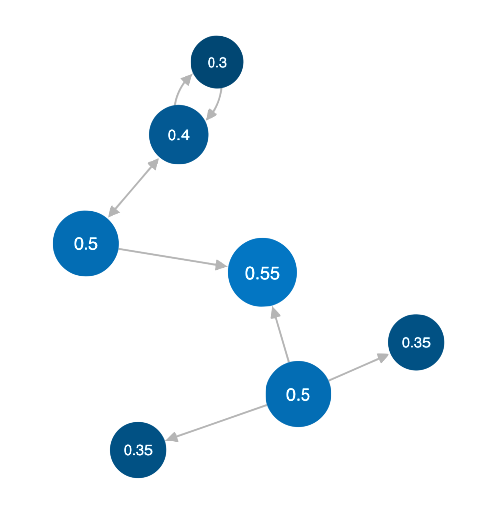
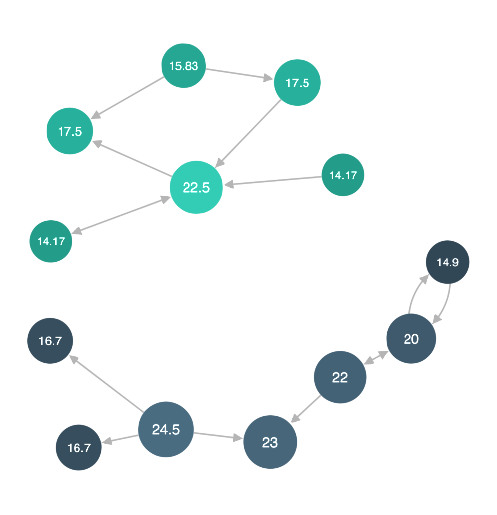
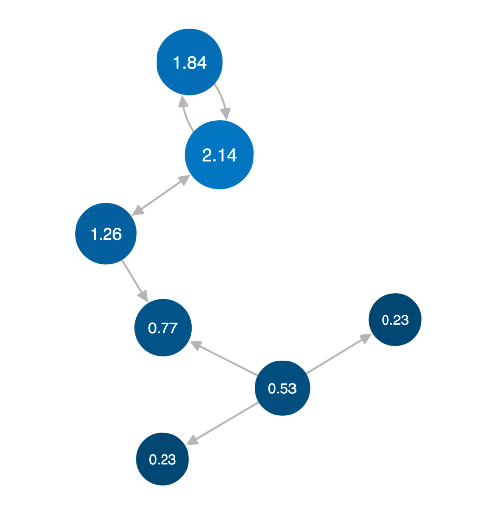
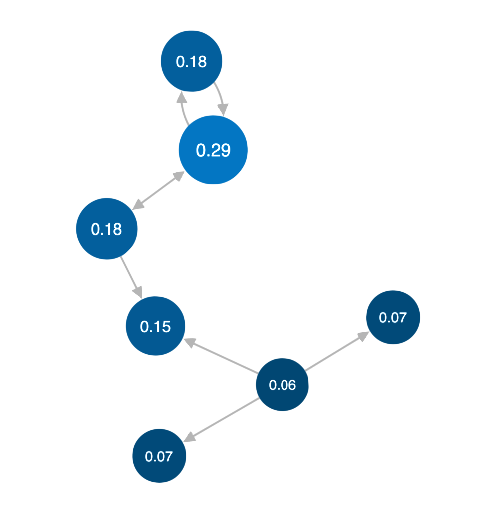
Like degree centrality, eigencentrality measures a node's
influence based on the number of links it has to other nodes
within the network. Eigencentrality then goes a step
further by also looking at how many links their connections
have, and so on throughout the connected network.
By calculating the extended connections of a node,
eigencentrality can identify nodes with influence over
the whole network, not just those directly connected to it.
Eigencentrality is a good ‘all-round’ SNA score, and is
useful for understanding human social networks, but also
for understanding networks like malware propagation.
In a graph with multiple disconnected components,
eigencentrality is calculated separately on each component.
The sum of the eigencentrality values in each component
equals the number of nodes in that component.
Link direction does not affect eigencentrality calculations.